leetcode刷题记录——链表
141 环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:

输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:

输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1
输出:false
解释:链表中没有环。
提示:
链表中节点的数目范围是 [0, 104]-105 <= Node.val <= 105pos 为 -1 或者链表中的一个 有效索引 。
思路
环形链表顾名思义就是链表中存在一个环,当节点遍历到能够连接到环的位置能够回到前面。
所以我们可以用快慢指针,快指针一次走两步慢指针一次走一步,只要这两个能够相遇则为有环,如果不能就表示无环。
代码
1 | |
时间复杂度
时间复杂度O(n),执行时间76ms,消耗内存18.8MB
这里提交后发现这个的执行时间还是太慢了,所以我们对这个进行优化。
优化思路
既然我们用两个指针会导致整个代码的速度变慢,把我们就只用一个指针,用一个集合去记录已经走过的位置,只要能够回来就表示这里有环,如果不能就表示无环。
1 | |
时间复杂度
时间复杂度O(n),执行时间46ms,消耗内存19.1MB
2 两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:

输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
示例 2:
输入:l1 = [0], l2 = [0]
输出:[0]
示例 3:
输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
输出:[8,9,9,9,0,0,0,1]
提示:
每个链表中的节点数在范围 [1, 100] 内
0 <= Node.val <= 9
题目数据保证列表表示的数字不含前导零
思路
这里需要提前知道题目没给的条件,这个是在实例中有体现,我们遇到加和为两位数后,我们需要进位,所以我们需要一个进位的变量。
这里我们需要用到一个divmod函数来解决这个问题,函数输入为两个数,返回值为一个元组,第一个元素为商,第二个元素为余数。
其余的就是取数、加和、下一个的问题了
代码
1 | |
时间复杂度
时间复杂度O(n),执行时间61ms,消耗内存16.4MB
21 合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:

输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = []
输出:[]
示例 3:
输入:l1 = [], l2 = [0]
输出:[0]
提示:
两个链表的节点数目范围是 [0, 50]
-100 <= Node.val <= 100
l1 和 l2 均按 非递减顺序 排列
思路
这里我们就还是设置两个节点,均为头结点的前一位,然后设置一个辅助节点,用来存储合并后的链表。
然后我们比较两个链表的头结点,谁小就把谁的头结点放到辅助节点的后面,然后把这个节点的指针指向下一个节点,然后继续比较,直到两个链表都为空。
最后把辅助节点的下一个节点作为合并后的链表的头结点。
代码
1 | |
时间复杂度
时间复杂度O(n),执行时间40ms,消耗内存16.4MB
138 随机链表的复制
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1: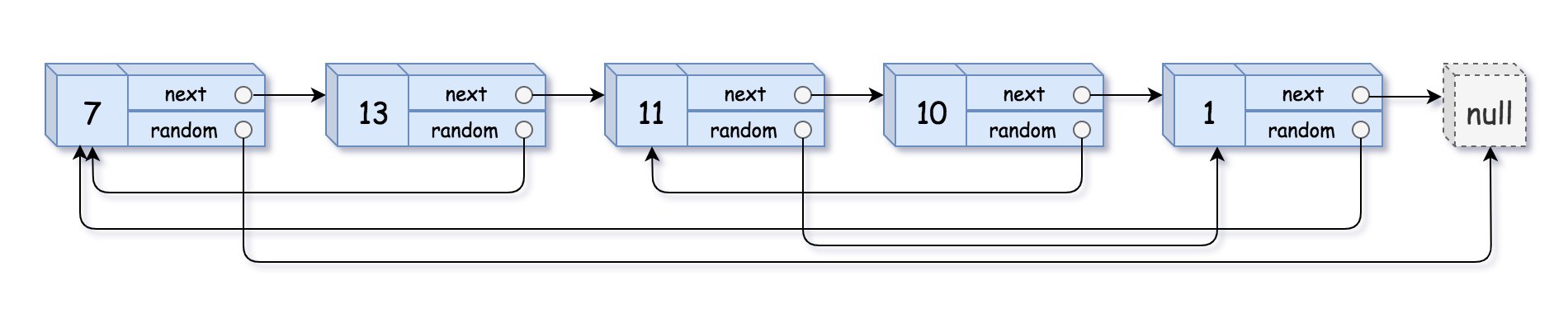
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:
输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:
输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
提示:
0 <= n <= 1000
-104 <= Node.val <= 104
Node.random 为 null 或指向链表中的节点。
思路
这里我们可以借助字典来实现。
首先明确一点,我们可以采用两次循环来完成,一次获取val,一次获取next和random
最后直接返回第一个节点即可。
代码
1 | |
时间复杂度
时间复杂度O(n),执行时间48ms,消耗内存17.2MB
92 反转链表 II
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
示例 1:
输入:head = [1,2,3,4,5], left = 2, right = 4
输出:[1,4,3,2,5]
示例 2:
输入:head = [5], left = 1, right = 1
输出:[5]
提示:
链表中节点数目为 n
1 <= n <= 500
-500 <= Node.val <= 500
1 <= left <= right <= n
思路
首先需要知道一点,我们在设置头结点前面一个虚拟节点的时候,需要用一个类似pre的字符去表示,直接使用头结点dummy会导致后续出现异常导致无法完全测试。
然后反转部分我的思路是直接原地操作,不进行拆开后后续拼接,所以时间复杂度上会相对来说高一些。之前反转链表中使用过拆开后拼接,这种情况下时间复杂度会降低,但是也会由于思路的混乱导致最后测试失败。
这里需要注意的另外一点是,我们这里只使用两个节点进行直接操作。刚开始我也使用了添加一个tail进行操作,但是会导致后续反转逻辑写起来比较复杂。
代码
1 | |
时间复杂度
时间复杂度O(n),执行时间46ms,消耗内存16.3MB
25 K 个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:

输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
示例 2:

输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]
提示:
链表中的节点数目为 n
1 <= k <= n <= 5000
0 <= Node.val <= 1000
思路
这里其实反转思路和前一道题一模一样。
需要注意的是我这里没用一个额外的数去累加计数,而是将整个需要反转的进行递归。
代码
1 | |
时间复杂度
时间复杂度O(n),执行时间37ms,消耗内存17.1MB
19 删除链表的倒数第 N 个节点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1
输出:[]
示例 3:
输入:head = [1,2], n = 1
输出:[1]
提示:
链表中结点的数目为 sz
1 <= sz <= 30
0 <= Node.val <= 100
1 <= n <= sz
思路
首先按照数组字符串的思路直接倒序遍历找到节点删除就可以,但链表是不能进行倒序遍历和直接获取长度的。所以我们就需要自己去通过循环得到相关的内容。
代码
1 | |
时间复杂度
时间复杂度O(n),执行时间39ms,消耗内存16.3MB
优化
这里我用了快慢指针去,思路上都差不多
1 | |
82 删除排序链表中的重复元素 II
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:

提示:
链表中节点数目在范围 [0, 300] 内
-100 <= Node.val <= 100
题目数据保证链表已经按升序 排列
思路
这里首先要注意一点也是我之前做了好几次一直过不去的原因。当我们发现两个节点值相同时,应该用一个变量去存储值,而不是直接进行后续的循环操作,直接进行操作将一直持续不断的遍历两个节点而非继续往后走。
代码
1 | |
时间复杂度
时间复杂度O(n),执行时间45ms,消耗内存16.3MB
61 旋转链表
给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。
示例 1:

输入:head = [1,2,3,4,5], k = 2
输出:[4,5,1,2,3]
示例 2:

输入:head = [0,1,2], k = 4
输出:[2,0,1]
提示:
链表中节点的数目在范围 [0, 500] 内
-100 <= Node.val <= 100
0 <= k <= 2 * 109
思路
首先知道我们每个节点往前移k个就相当于倒数第k个节点之后的节点移到头结点前。
其次我们计算长度后,我们对k进行操作,k就相当于k对长度取余,因为k大于长度时我们进行后续操作就相当于走了一圈又继续走。
代码
1 | |
时间复杂度
时间复杂度O(n),执行时间40ms,消耗内存16.4MB
86 分割链表
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:

输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2
输出:[1,2]
提示:
链表中节点的数目在范围 [0, 200] 内
-100 <= Node.val <= 100
-200 <= x <= 200
思路
看到题目第一反应是二分法,大于k的在右边,小于的在左边。
然后我们就可以用相似的思路去做。我们建立两个表用来存储大于和小于的节点,其次我们在遍历后直接将两个表一拼接就直接完成了。
切记我们需要在最后将大于的那个表的尾节点指向None,不然就会形成环。
代码
1 | |
时间复杂度
时间复杂度O(n),执行时间38ms,消耗内存16.3MB
146 LRU 缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
1 <= capacity <= 3000
0 <= key <= 10000
0 <= value <= 105
最多调用 2 * 105 次 get 和 put
思路
这道题有那么亿点点绕,所以思路上写的比较详细
首先我们需要完成两个操作
get(key): 如果key存在于缓存中,则返回对应的值,否则返回-1。put(key, value): 将key-value对插入缓存中。如果key已经存在,更新其值;如果key不存在并且缓存已满,则移除最近最少使用的项。
然后我们来说明如何实现
- 初始化:构建一个空哈希表和一个带有哨兵头尾节点的双向链表
get(key):- 如果不存在,直接返回-1
- 如果存在,找到对应节点,将其从链表中移除并添加到链表末尾,以表示它是最近使用的元素
put(key, value):- 如果key已经在缓存中,更新其值,并将该节点移动到链表的末尾。
- 如果key不存在,创建一个新节点并插入到链表末尾。
- 如果插入后缓存超出了容量,移除链表头部的节点(即最近最少使用的节点),并从哈希表中删除对应的键。
- 操作解释
_add:将节点添加到双向链表的末尾,这表示该节点是最新被访问的。_remove:将节点从双向链表中删除,这个操作主要用于在get或put操作时调整节点的位置,以及在缓存容量超出限制时移除最老的节点。
代码
1 | |
时间复杂度
时间复杂度O(1),执行时间457ms,消耗内存75.6MB